Introdução à Recuperação de Informação #03 – Visão lógica de documentos

👊😎 Saudações, galera! No post anterior fizemos uma breve discussão sobre os modelos clássicos de Recuperação de informação (RI), considerando informações textuais.
👉 Hoje vamos entender como os documentos podem ser representados logicamente. Bora! 🚀
Representação de documentos
Antes de estudar com mais detalhes os modelos de RI, é importante compreendermos como os documentos textuais são representados por um computador. Essa representação também é chamada de visão lógica.
O texto puro, como ele se apresenta, sem nenhum tipo de processamento, é chamado de visão full-text (texto completo). Em datasets muito grandes, implementar sistemas de RI que consideram a visão full-text possui um alto custo computacional.
Assim, é comum usar técnicas de pré-processamento, que objetiva reduzir o tamanho e a complexidade dessas representações. Isso significa que um documento pode ser reduzido a um conjunto de palavras-chave representativas (vocabulário controlado), que determinam o seu contexto como se fosse uma camada semântica.
Na figura a seguir são mostrados todos os passos necessários para a construção do vocabulário controlado de um documento.
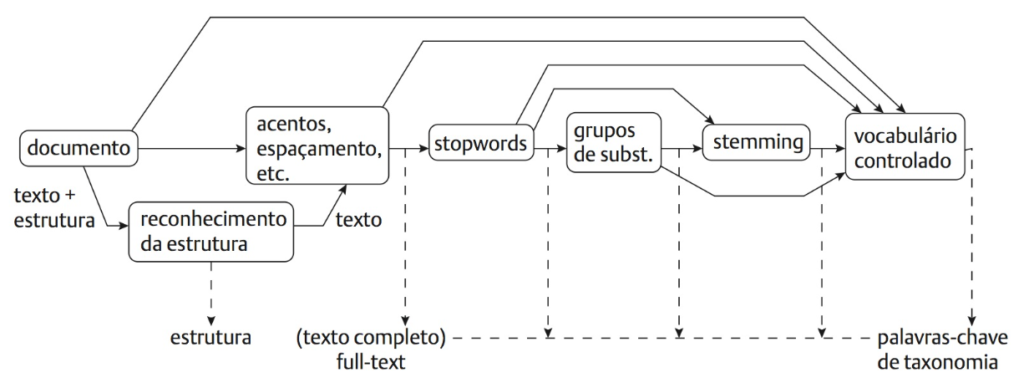
Fonte: Baeza-Yates e Ribeiro Neto (2013)
Detalhando um pouco mais, podemos inferir mediante a figura:
- O primeiro passo é compreender a estrutura do documento, visto que isso é imprescindível na construção de algoritmos de pré-processamento;
- O segundo passo é a remoção das stopwords, ou seja, palavras que possuem pouco ou nenhum poder discriminativo, como artigos e preposições;
- Após isso podemos agrupar e classificar os substantivos, gerando o vocabulário controlado;
- Ou, antes disso, realizar o stemming (redução da palavra ao seu radical – veja exemplo aqui!) ou até mesmo a lematização (redução da palavra à sua forma de origem no singular e masculino – veja exemplo aqui!);
- Finalmente, criamos uma representação do documento por meio de uma matriz de termos contendo o vocabulário controlado.
Matriz de termos e documentos
Tomemos como exemplo os seguinte dataset de documentos textuais:
- Sun is the biggest celestial body in our solar system.
- Earth is our planet, not Mars!
- The moon orbits Earh. Earth orbits sun.
Convertendo todas as palavras em minúsculas, retirando os pontos (e acentos se houver), removendo as stopwords e fazendo a lematização, temos:
- sun big celestial body solar system
- earth planet mars
- moon orbit earth earth orbit sun
Assim, podemos criar a seguinte matriz de termos e documentos, onde as colunas são compostas pelo vocabulário controlado, as linhas pelos documentos e as células mostram a frequência de cada termo no documento.
| sun | big | celestial | body | solar | system | earth | planet | mars | moon | orbit | |
| d1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| d2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| d3 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 1 | 2 |
A frequência de um termo em um documento representa sua importância dentro dele, assim como a frequência dele em todo o dataset. Assim, a matriz de termos e documentos fornece um meio para recuperar informações considerando apenas a frequência dos termos da consulta. Essa abordagem não é eficiente, mas dá uma ideia de como o ranqueamento é criado.
Por exemplo, dada uma consulta q = “earth”, considerando a frequência do termo q, um hipotético sistema de RI, considerando o modelo Booleano, recuperaria os documentos d2 e d3, sendo o documento d3 mais preciso em relação a q. Isto é, se consideramos apenas a frequência dos termos.
A matriz de consulta e termos e documentos ficaria assim:
| q | d1 | d2 | d3 |
| earth | 0 | 1 | 2 |
Conclusão
A representação lógica de um documento é imprescindível para a RI. Apesar de existirem inúmeras técnicas de análise semântica de texto, elas envolvem alta complexidade e alto custo computacional.
Assim, os modelos clássicos de RI, que usam a abordagem de bag of word (saco de palavra), fornecem um meio eficiente e simples para a concepção de sistemas de RI.
Nos próximos posts estudaremos com mais detalhes os modelos clássicos de RI, além implementá-los na linguagem Python.
Até lá! 👊😎
Referências
BAEZA-YATES, R.; RIBEIRO-NETO, B. Recuperação de Informação: Conceitos e Tecnologia das Máquinas de busca. 2 ed. Porto Alegre: Grupo A, 2013.




