Introdução à Recuperação de Informação #01 Introdução

👊😎 Saudações, galera! Estou iniciando uma série que trata de um dos temas que tenho estudado ultimamente: Recuperação de Informação.
Se você é profissional de TI, ou é apenas um entusiasta da área, recomendo a leitura, pois é uma tema extremamente relevante. Neste primeiro post vou introduzir o tema. Bora! 🚀
Introdução
A Recuperação de Informação (RI ou IR, abreviação do termo em inglês, Information Retrieval) é uma área da Ciência da Computação que pesquisa métodos para representar, armazenar, organizar e prover acesso a conteúdos informacionais, como documentos estruturados e semiestruturados, objetos multimídia, páginas web, entre outros (BAEZA-YATES; RIBEIRO NETO, 2013).
Apesar do termo Recuperação de Informação ser relativamente novo, sendo supostamente criado pelo cientista da computação Calvin Mooers nos anos 1950, o tema remete a muitos séculos atrás, com a preocupação em preservar fatos e conhecimentos para as gerações futuras.
De fato, no decorrer da história, a humanidade sempre esteve preocupada em desenvolver tecnologias para armazenar, organizar, distribuir e, principalmente, acessar informações de maneira rápida.
Na antiguidade, a biblioteca mais conhecida é a famosa Biblioteca de Alexandria, assim nomeada em homenagem ao emblemático rei macedônio Alexandre, o Grande (356-323 a.C). Durante mais de sete séculos, a Biblioteca Real, além de outras bibliotecas da cidade, fizeram com que Alexandria fosse a capital intelectual do ocidente.
Nesse sentido, os livros e, principalmente, as bibliotecas exerceram e ainda exercem um papel fundamental na história, visto que preservam a memória coletiva da raça humana.
Com o advento da internet e suas tecnologias subjacentes, a RI tem ganhado destaque nas mais diversas áreas, considerando que praticamente todo o conhecimento humano foi digitalizado ou está em processo de digitalização.
Portanto, criar meios eficientes de acesso à informação não é interesse apenas de historiadores, jornalistas e outros profissionais que se relacionam diretamente com ela, mas de todos os cidadãos.
Que tipo de problema a RI resolve?
Segundo o site Seed Scientific, em 2025 o mundo gerará cerca de 460 exabytes de dados por dia. Lembrando que 1 exabyte equivale a 1 bilhão de terabytes. Esses números exigem a concepção de sistemas de RI de diferentes naturezas e com diferentes complexidades.
De fato, os usuários de um sistema de RI possuem diferentes interesses, logo, as consultas podem ser simples, permitindo ao usuário usar termos de indexação (palavras-chave) relacionados ao seu interesse. Eles também podem executar consultas mais complexas, que envolvem não apenas o aspecto sintático das palavras, mas também a semântica, a relação entre as palavras e o contexto.
Um exemplo de consulta complexa seria algo como: “Encontre todos os deputados federais que são contra a legalização das drogas”.
Essa descrição textual mostra uma necessidade específica de um usuário, mas não necessariamente a melhor formulação de uma consulta para um sistema de RI, considerando que a informação desejada pode estar em um conjunto de dados não estruturados.
Assim, é muito comum que o usuário traduza sua necessidade em uma sequência de consultas, ou, de maneira mais intuitiva, utilize termos de indexação para recuperar os documentos mais úteis ou mais relevantes, assim como fazemos quando usanmos o buscador Google.
“[…] o objetivo principal de um sistema de RI é recuperar todos os documentos que são relevantes à necessidade de informação do usuário e, ao mesmo tempo, recuperar o menor número possível de documentos irrelevantes”
BAEZA-YATES; RIBEIRO NETO, 2013.
Portanto, um sistema de RI deve, de certa maneira, interpretar o conteúdo dos documentos da coleção (dataset) e classificá-los (ranqueamento) considerando o grau de relevância de acordo com a consulta do usuário.
A ideia de relevância é imprescindível para a RI, pois os documentos recuperados pela consulta podem ser relevantes ou irrelevantes de acordo com uma série de critérios, determinados pelo interesse do usuário. Para Baeza-Yates e Ribeiro Neto (2013), “[…] a relevância é um julgamento pessoal que depende da tarefa a ser resolvida e do seu contexto”.
É importante salientar que o foco de um sistema de RI é recuperar informações e não dados. Portanto, há muitas técnicas nos de sistemas de RI, desde as que usam apenas termos de indexação para consulta, até as mais sofisticadas, que usam inclusive Inteligência Artificial.
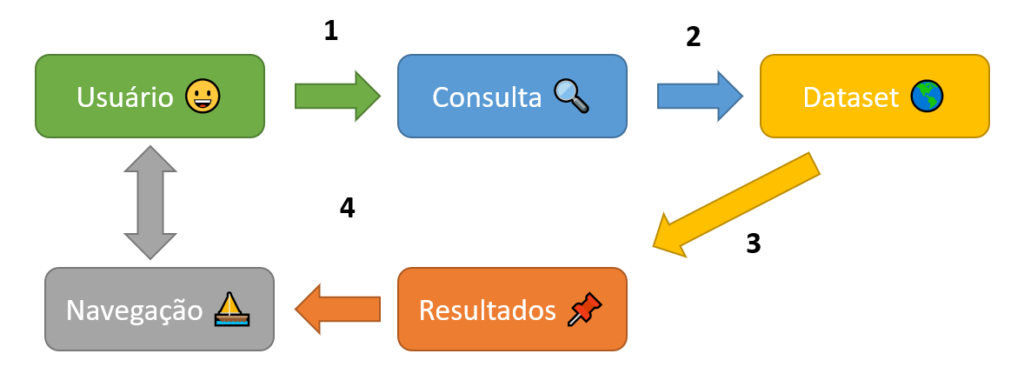
Convém destacar que ranqueamento dos resultados, ou seja, a classificação mediante a relevância dos documentos retornados, é importantíssimo em RI. Os primeiros resultados devem ser os mais relevantes e, a medida que o usuário navega, os resultados tornam-se menos relevantes.
Recuperação da Informação VS Recuperação de Dados
Pense num sistema que recupere com exatidão os dados de um banco de dados relacional (dados estruturados) mediante uma consulta, por exemplo: “encontre todos os clientes do sexo masculino com idade superior a 18 anos“.
Essa necessidade pode ser traduzida em uma consulta da linguagem SQL (Structured Query Language), algo como: SELECT * FROM client WHERE age > 18 AND gender = “M”.
A consulta SQL irá retornar exatamente os dados que o usuário precisa, nada a mais, nada a menos. Isso é possível porque a principal característica dos bancos de dados relacionais é a relação bem definida entre os conjuntos de dados (tabelas) que expressam o domínio da aplicação.
“Bancos de dados relacionais são conjuntos de dados (datasets) estruturados”
Por sua vez, um sistema de RI faz suas consultas em conjuntos de dados não estruturados ou semiestruturados, logo ele deve permitir ao usuário recuperar informações sobre um determinado assunto, ao invés de recuperar dados exatos que satisfaçam plenamente uma consulta.
“Um sistema de RI realiza consultas em conjuntos de dados semiestruturados ou não estruturados”
Assim, um sistema de RI retorna um conjunto de resultados, ou documentos, considerando, por exemplo, sinônimos dos termos pesquisados, a presença ou ausência deles e outras relações sintáticas e/ou semânticas, visto que o conjunto de dados usados são semiestruturados ou não estruturados.
Isso significa que o usuário de um sistema de RI poderá explorar os resultados, mediante navegação e análise criteriosa dos documentos.
Conclusão
Considerando a quantidade astronômica de informações que geramos na era da Internet, a RI possui grande importância, visto que, ao contrário de um banco de dados relacional, que possui dados estruturados, a RI se ocupa de procurar por informações em bases de dados semiestruturados e não estruturados.
Portanto, a concepção de sistemas de RI possui um papel fundamental no acesso à informação nos dias atuais.
No próximo post iremos discutir sobre modelagem de sistemas de RI. Até lá! 👊😎
Referências
BAEZA-YATES, R.; RIBEIRO-NETO, B. Recuperação de Informação: Conceitos e Tecnologia das Máquinas de busca. 2 ed. Porto Alegre: Grupo A, 2013.




